Esse texto foi originalmente publicado em 12 Fatores: conheça as boas práticas da metodologia de desenvolvimento de softwares
A computação em Cloud tem trazido uma série de revoluções e inovações na forma com que recursos computacionais são consumidos. Além de permitir que grandes corporações evoluam suas plataformas para torná-las mais ágeis e escaláveis, ela ainda permite acesso fácil, rápido e relativamente barato a soluções que antes eram restritas a empresas de grande porte.
Entretanto, para conseguirmos explorar todos os benefícios que um ambiente em cloud pode oferecer, precisamos entender também como as aplicações são desenvolvidas nela, considerando não somente aspectos de infraestrutura.
É com esse objetivo que, nesse artigo, vamos falar sobre as 12 práticas de desenvolvimento recomendadas pela metodologia 12 Fatores.
O que são os 12 Fatores
A metodologia 12 Fatores é composta por um conjunto de boas práticas para construção de aplicações para Cloud. Entre seus principais objetivos, ela visa explorar os benefícios das plataformas, favorecer a portabilidade máxima entre os ambientes de execução, aumentar a agilidade com atualizações frequentes, escalar sem causar mudanças significativas e diminuir o custo e tempo de onboarding de novas pessoas desenvolvedoras nos times.
Seus princípios estão organizados em 12 pilares:
- Base de código
- Dependências
- Configurações
- Serviços de apoio
- Build, Release, Run
- Processos
- Port Binding
- Concorrência
- Descartabilidade
- Paridade entre desenvolvimento e produção
- Logs
- Processos Administrativos
Eles foram documentados pela primeira vez em 2011, por pessoas da empresa Heroku, uma provedora de PaaS (Plataform as a Service). A partir da experiência e lições aprendidas com a forma com que clientes utilizavam a plataforma deles, foram descritas práticas que podem ser aplicadas independentemente de linguagens de programação ou de qual plataforma está sendo utilizada.
Pode ser que você considere alguns deles óbvios ou básicos demais. No entanto, ainda assim, caso eles não forem aplicados, é possível que uma série de problemas futuros sejam gerados — e potencializados em um ambiente na Cloud. Você provavelmente também vai perceber que vários desses fatores estão interligados e apresentam dependências e condições básicas.
Nesse post, iremos falar sobre os 6 primeiros fatores da lista.
1. Base de código
O código-fonte é a base de tudo. Então, se estamos pensando em ter mais agilidade e rastreabilidade, cada aplicação deve ter seu próprio código-fonte, que poderá ser rastreado em um sistema de controle de versão — e a partir dele, poderão ser gerados vários deploys com versões diferentes. Nesse caso, cada deploy ainda poderá ser executado em um ambiente diferente, como Desenvolvimento, Homologação e Produção, por exemplo.
Uma aplicação não deve possuir mais do que uma base de código. Ou seja, não é recomendado termos bases diferentes de acordo com o ambiente, já que isso pode tornar a rastreabilidade e o controle do que está sendo executado mais complexo. Além disso, duas aplicações não devem compartilhar uma mesma base de código. Se houver oportunidade de reutilização de alguma funcionalidade, ela deve ser feita através de uma dependência (como uma referência a uma biblioteca, por exemplo) ou de um serviço, com bases de códigos separadas.
Apesar de ser uma prática básica, muitas pessoas já devem ter se deparado com casos em que não era mais possível acessar códigos-fontes de aplicações, por qualquer que seja a razão. Isso traz enormes riscos para os negócios suportados por estas aplicações, já que qualquer evolução ou correção de problemas pode se tornar impossível.
Atualmente, o padrão do mercado para versionamento de código-fonte é o onipresente repositório Git. Portanto, esse fator poderia ser atendido com o armazenamento dos códigos-fontes da aplicação em um repositório.
2. Dependências
Dependências de aplicações devem ser declaradas explicitamente. Nesse caso, entenda como “dependência” qualquer pacote ou biblioteca que a aplicação precise para funcionar corretamente. Dessa forma, uma aplicação não deve contar com a existência de bibliotecas, pacotes e nem mesmo ferramentas de sistema operacional no ambiente em que será executada. É preciso considerar que o ambiente de execução da aplicação é heterogêneo e pode mudar, como de fato acontece.
Se você ainda tem dúvidas, lembre-se da evolução ocorrida na transição de servidores físicos (bare metal) para máquinas virtuais, que evoluíram para containers e então para ambientes serverless (como FaaS — Function as a Service, por exemplo).
Além disso, as dependências ainda devem ser isoladas por aplicação — ou seja, não é uma boa prática termos uma dependência instalada de forma geral no sistema operacional de um computador ou servidor. Se tivermos várias aplicações compartilhando uma mesma dependência, precisaremos coordenar os times responsáveis por cada aplicação para realizarmos atualizações, por exemplo, o que com certeza impactará nossa velocidade e autonomia. Ao mesmo tempo, nem todas as aplicações utilizarão a mesma versão da dependência, o que pode causar diversos problemas.
Quando declaramos explicitamente as dependências utilizadas, conseguimos empacotá-las junto à aplicação, tornando-a mais autocontida (já que a aplicação possuirá todos os requisitos para ser executada). Dessa forma, aumentamos a portabilidade e a sua capacidade de ser executada em vários ambientes, além de simplificarmos a sua configuração.
A forma exata com que vamos tratar e resolver dependências varia de acordo com a plataforma ou linguagem de desenvolvimento utilizada, mas qualquer linguagem moderna possui mecanismos para executar os passos que detalhamos acima.
Alguns exemplos são a Maven para aplicações Java, NuGet para aplicações .NET, Pip para Python e npm para Node.js. Containers também podem nos ajudar a tornar uma aplicação mais autocontida, isolada e portável.
3. Configurações
As configurações são as informações que podem variar entre os diferentes ambientes, como Desenvolvimento, Homologação, Produção etc. Entre elas, podemos falar sobre credenciais, endereços de bancos de dados e URLs de APIs, além de web services e servidores de SMTP, por exemplo.
A boa prática recomendada pela metodologia é de que as configurações devem estar separadas do código-fonte e disponíveis no ambiente em que a aplicação estiver sendo executada. Dessa forma, a mesma aplicação pode ter sua execução em ambientes diferentes sem sofrer alterações e com base nas configurações de cada ambiente.
Um bom indicador para saber o quanto a sua aplicação está aderente a este fator é imaginá-la sendo uma aplicação open source: se o código-fonte da aplicação fosse aberto e publicado no GitHub, por exemplo, alguma informação sigilosa ou sensível seria exposta, como por exemplo um usuário e senha? Se a resposta for sim, então é melhor rever as configurações.
Existem várias formas de configurar uma aplicação — o importante é que as configurações não fiquem hardcoded no código-fonte.
4. Serviços de Apoio
Serviços de Apoio são qualquer serviço do qual a aplicação dependa, e que seja consumido via rede, como por exemplo serviços de armazenamento de dados, sistemas de mensageria, mecanismos de cache, serviços de segurança ou serviços que forneçam funcionalidades de negócio. O acesso aos Serviços de Apoio é feito com base nas informações obtidas nas Configurações, detalhadas no tópico anterior.
O ponto-chave dessa boa prática é que deve haver um baixo acoplamento entre a aplicação e seus serviços de apoio. O ideal é que a troca de algum serviço de apoio por outro equivalente seja transparente para a aplicação, sem a necessidade de realizar alterações no código ou até uma nova implantação. Caso isso não seja possível, deve-se limitar ao máximo as alterações, de preferência em partes específicas e centralizadas do código, evitando mudanças muito grandes ou estruturais na aplicação.
5. Build, Release, Run
Esse fator trata de como, a partir do código-fonte da aplicação, armazenado na Base de Código, também deve existir um processo que seja responsável pela obtenção das dependências (conforme explicado no fator número 2) e pela compilação da aplicação (quando aplicável), seu empacotamento, testes e geração de um artefato que estará pronto para ser executado em algum ambiente.
Os artefatos produzidos devem ser versionados e imutáveis, o que garante que qualquer mudança deva passar por todo processo estabelecido. Isso gera uma nova versão dos artefatos e evita que etapas sejam puladas (por exemplo, não se deve pular a etapa de testes e também não é recomendado mudar o código da aplicação diretamente em Produção).
Uma ótima prática é contar com a ajuda de pipelines automatizadas de CI/CD (Continuous Integration/Continuous Delivery), que irão garantir consistência e padronização na execução das várias etapas do fluxo. Além disso, elas também garantem que a aplicação será compilada sempre da mesma maneira e com a automação dos testes, o que aumenta a agilidade nas entregas e reforça a confiança de que as alterações não irão provocar problemas, uma prática que pode ser aliada às estratégias de zero downtime deployment.
Em cenários mais maduros, ainda é possível optar pelo Continuous Deployment, quando novas versões da aplicação são implantadas automaticamente em produção, desde que as condições definidas na pipeline sejam respeitadas.
Existe uma infinidade de ferramentas que podem nos ajudar com build&run, como Jenkins, GitLab CI, AWS CodePipeline, AWS CodeBuild, GitHub Actions etc. Entretanto, é importante destacar que essas ferramentas são somente uma parte da questão. Outros aspectos precisam ser considerados: a aplicação deverá ser desenvolvida de forma que possa ser testada automaticamente, estar preparada para o uso de estratégias de zero downtime deployment, etc.
6. Processos
Esse fator determina que a aplicação seja executada como um ou mais processos (ou instâncias) que devem ser stateless — ou seja, não devem armazenar dados localmente entre as requisições.
Dessa forma, cada requisição recebida por um processo de uma aplicação deve ser tratada de forma independente das requisições anteriores ou posteriores, e a aplicação não deve assumir que algum dado armazenado na memória ou no disco estará disponível em uma futura requisição. Qualquer processo da aplicação deve poder processar qualquer requisição, e qualquer dado que precisar ser persistido deverá ser armazenado em um Serviço de Apoio específico para essa finalidade.
Para entender a importância dessa boa prática, vamos a um exemplo. Começaremos com o modelo que deve ser evitado (ou seja, o modelo de uma aplicação stateful, que depende de dados armazenados localmente entre as requisições).
Imagine um cenário em que temos consumidores de uma aplicação (que podem ser pessoas usando um browser ou outras aplicações) acessando o endereço de um balanceador de carga, que por sua vez distribui a requisição entre várias instâncias da aplicação. No cenário de uma aplicação stateful, isso significa que a partir do primeiro acesso de um consumidor, todas as requisições dele serão encaminhadas para a mesma instância. Dessa forma, é estabelecida uma dependência (também conhecida por afinidade de sessão) entre o consumidor e ela. A figura a seguir representa como isso funciona:
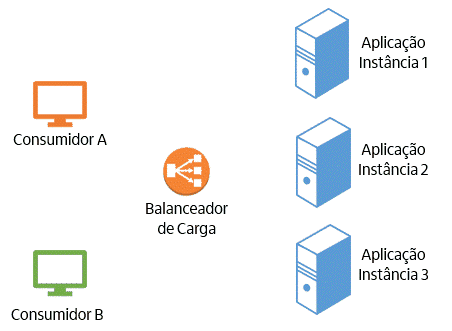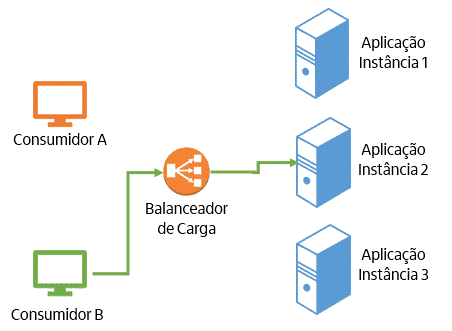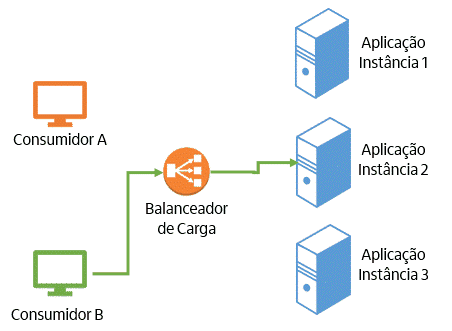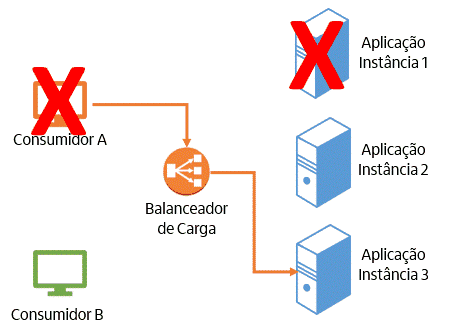
O modelo stateful traz uma série de problemas. São eles:
- Caso haja algum problema naquela instância e ela precise ser encerrada, os dados mantidos localmente serão perdidos. A próxima requisição daquele consumidor será encaminhada pelo balanceador de carga para uma outra instância da aplicação, mas essa não terá os dados, o que provocará algum tipo de inconsistência. Por exemplo, em uma loja virtual, isso poderia significar perder os produtos do carrinho de compras, fazendo com que o cliente tivesse que incluir os produtos novamente. Com certeza, ele não ficaria nada feliz.
- Ainda considerando o cenário anterior, em que uma instância da aplicação é encerrada, isso nem sempre acontece por causa de um problema. A Cloud é um ambiente elástico: se a demanda da aplicação aumentar, podem ser provisionadas mais instâncias da aplicação e mais recursos (máquinas virtuais, containers etc). Quando a demanda diminuir, esses recursos também podem ser desalocados. No cenário de uma aplicação stateful, uma instância da aplicação não poderá ser encerrada até que todos os consumidores atendidos por ela concluam suas atividades. Se isso não for respeitado, ocorrerá o problema descrito no item anterior. Dessa forma, recursos acabam ficando alocados mais tempo do que o necessário, o que causa desperdício financeiro.
- Caso o consumidor faça uso muito pesado da aplicação, ele poderá sobrecarregar a instância da aplicação que o está atendendo. Dessa forma, mesmo que haja outras instâncias da aplicação ociosas, as requisições desse usuário não poderão ser balanceadas entre elas. Isso gerará problema de performance para aquele consumidor e até mesmo poderá provocar a queda daquela instância.
Agora, vamos explicar como uma aplicação stateless funciona na prática. A aplicação não armazena dados localmente entre as requisições, ou seja, cada requisição é independente das outras. Caso seja necessário ter acesso a dados entre as requisições, eles devem ficar armazenados em algum mecanismo específico para isso, onde todas as instâncias da aplicação tenham acesso. Assim, a requisição pode ser encaminhada para qualquer instância da aplicação. A figura abaixa representa esse modelo:
O modelo stateless traz diversas vantagens:
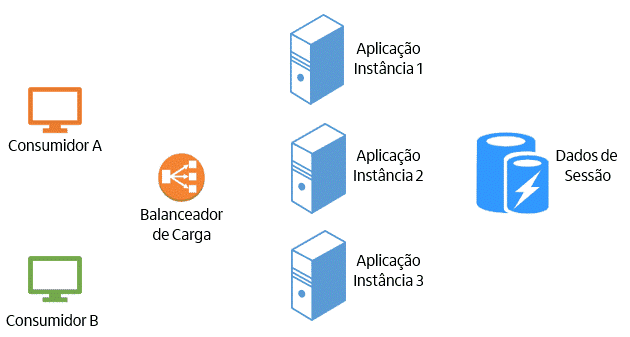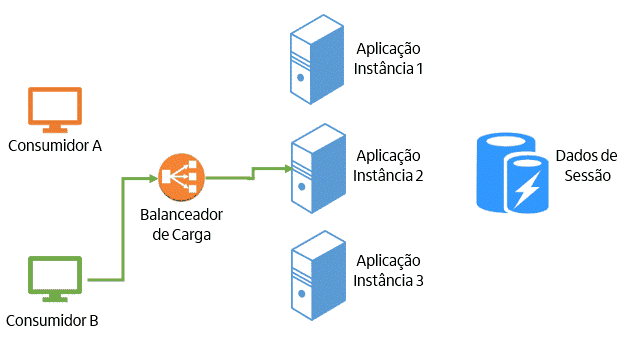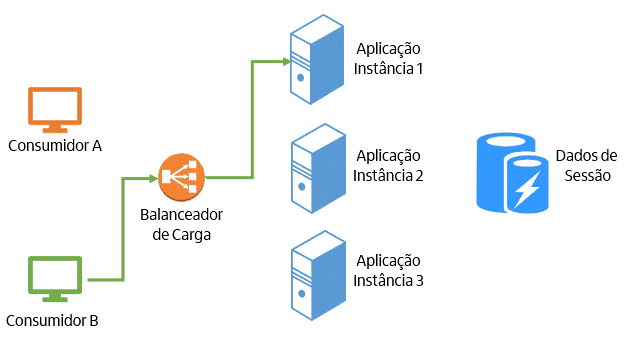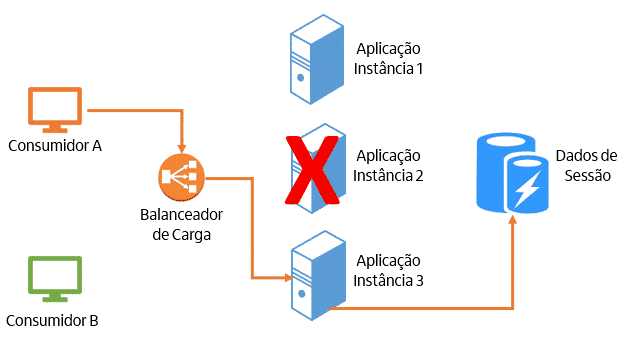
- Caso haja algum problema, a instância pode ser encerrada e não haverá perda de dados, pois eles não são armazenados localmente. A próxima requisição daquele consumidor será encaminhada pelo balanceador de carga para uma outra instância da aplicação disponível, que será capaz de realizar o processamento. O consumidor nem perceberá que isso ocorreu.
- Quando houver aumento de demanda da aplicação, novas instâncias e novos recursos serão provisionados e poderão ser utilizados rapidamente por qualquer consumidor. Quando a demanda diminuir, os recursos podem ser desalocados rapidamente, pois não existe afinidade entre consumidores e as instâncias da aplicação. Há um uso mais eficiente dos recursos disponíveis e evita-se desperdícios financeiros.
- Caso algum consumidor faça uso muito pesado da aplicação, essa carga poderá ser distribuída para todas as instâncias disponíveis da aplicação. Se necessário, novas instâncias poderão ser provisionadas. Não há sobrecarga de uma instância específica, já que as requisições são distribuídas de forma mais equilibrada entre todas as instâncias da aplicação e o consumidor não tem sua performance prejudicada.
A inclusão dessa camada de armazenamento de dados de sessão traz uma maior complexidade. Ela será um outro componente da arquitetura da aplicação e deve ser utilizado com muita atenção para que não se torne um ponto único de falha, mas é o preço a se pagar pelos benefícios oferecidos. Quando se fala em dados de sessão, normalmente, utiliza-se de algum mecanismo de cache, como Redis ou Memcached.
No próximo post, serão explicados os seis fatores restantes e como eles ajudam no desenvolvimento de aplicações para Cloud.